Replication of Partition: 장애를 대비하기 위한 기술

Producer/Consumer는 Leader와만 통신: follower는 복제만
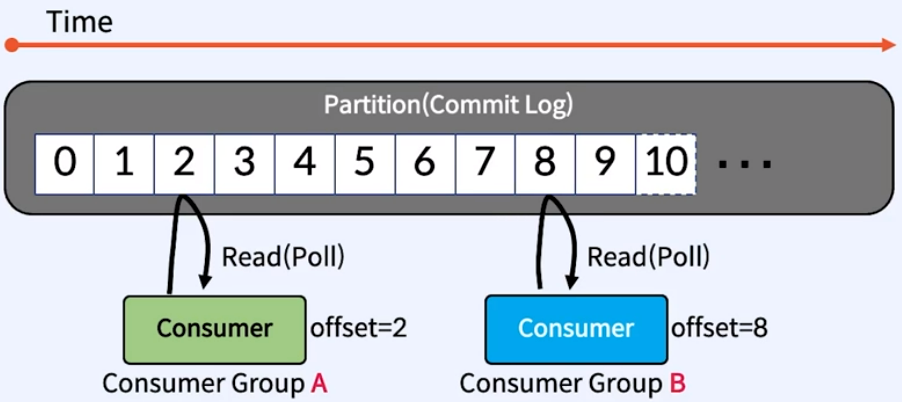
Producer는 Leader만 Write하고 Consumer는 Leader로부터만 Read함
Follower는 Broker 장애시 안정성을 제공하기 위해서만 존재
Follower는 Leader의 Commit Log에서 데이터를 가져오기 위해 요청(Fetch Request)으로 복제

Leader 장애 -> 새로운 Leader를 선출
Kafka 클러스터는 Follower 중에서 새로운 Leader를 선출
Client(Producer/Consumer)는 자동으로 새 Leader로 전환

Partition Leader에 대한 자동 분산: Hot Spot 방지
auto.leader.rebalance.enable: 기본값 enable
leader.imbalance.check.interval.seconds: 기본값 300 sec
. 300초마다 leader 분산에 불균형 여부 check
leader.imbalnce.per.broker.percentage: 기본값 10
. 다른 브로커보다 10% 이상 더 많이 가져가면 불균형으로 판단

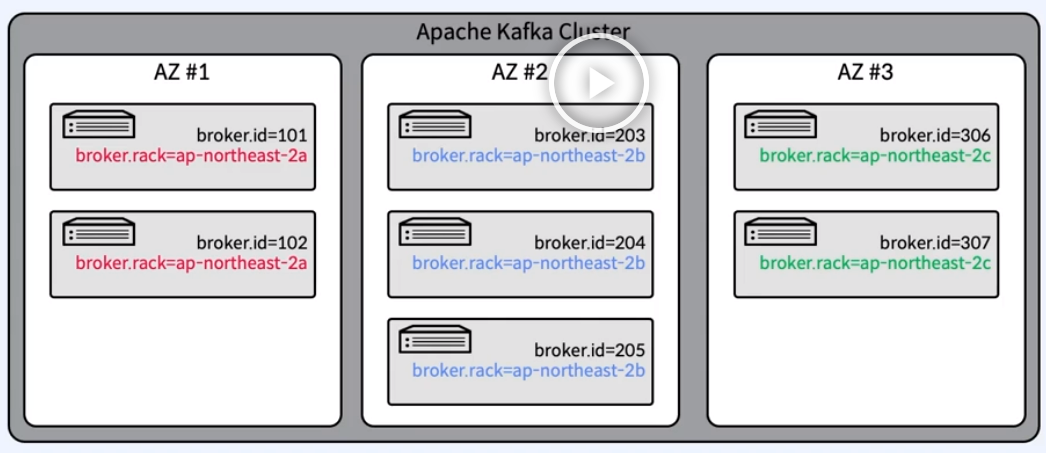
Rack Awareness: Rack간 분산하여 Rack 장애를 대비
동일한 Rack 혹은 Available Zone상의 Broker들에 동일한 "rack name" 지정
복제본(Replica-Leader/Follower)은 최대한 Rack 간에 균형을 유지하여 Rack 장애 대비
Topic 생성시 또는 Auto Data Balancer/Self Balancing Cluster 동작 때만 실행
'~2022 > Apache Kafka' 카테고리의 다른 글
| [Kafka] Consumer (0) | 2022.04.07 |
|---|---|
| [Kafka] Producer (0) | 2022.04.07 |
| [Kafka] Broker, Zookeeper (0) | 2022.04.07 |
| [Kafka] Topic, Partition, Segment (0) | 2022.04.06 |
| [Kafka] server.properties (0) | 2022.04.06 |