[레거시 데이터 아키텍처]
- 서비스에서 생성된 모든 데이터를 저장
- 필요에 따라 데이터를 조합하여 파생 데이터를 만듦
- 최종 사용할 서비스/사용자를 위해 서빙 데이터를 저장

- 레거시 데이터 아키텍처의 단점
초기 빅데이터 플랫폼은 End-to-End로 각 서비스 앱으로부터 데이터를 배치로 모았었는데, 이러한 구조는 유연하지 못했고 실시간으로 생성되는 데이터들에 대한 인사이트를 서비스 앱에 빠르게 전달하지 못하는 단점이 있었습니다.
또한 원천 데이터로부터 파생된 데이터의 히스토리를 파악하기가 어려웠고, 계속되는 데이터의 가공으로 인해 데이터가 파편화되면서 데이터 거버넌스를 지키기 어려웠습니다.
이를 해결하기 위해 개선한 아키텍처가 람다 아키텍처입니다.
[람다 아키텍처]
- 배치 레이어: 배치성 데이터를 모아서 특정 시간마다(시간, 일, 월 단위) 일괄 처리(=배치 데이터 처리)
- 스피드 레이어: 서비스에서 생성되는 원천 데이터를 실시간으로 분석(=실시간 데이터 처리)
- 서빙 레이어: 배치/스피드 레이어에서 처리한 데이터(가공된 데이터)를 최종 저장

배치 데이터에 비해 낮은 지연으로 분석이 필요한 경우, 스피드 레이어를 통해 데이터를 분석할 수 있습니다.
스피드 레이어에서 가공,분석된 실시간 데이터는 사용자 또는 서비스에서 직접 사용할 수 있지만, 필요한 경우 서빙 레이어로 데이터를 보내서 저장하고 사용합니다.
** 람다 아키텍쳐에서 카프카는 스피드 레이어에 위치
-> 서비스 애플리케이션들의 실시간 데이터를 짧은 지연 처리/분석할 수 있기 때문
- 람다 아키텍처의 단점
데이터를 분석/처리하는데 필요한 로직이 두벌로 각각의 레이어에 따로 존재한다
배치 데이터와 실시간 데이터를 융합하여 처리할 때 다소 유연하지 못한 파이프라인을 생성해야 한다.
데이터를 배치 처리하는 레이어와 실시간 처리하는 레이어를 분리한 람다 아키텍처는 데이터 처리 방식을 명확히 나눌 수 있었지만, 레이어를 두 개로 나뉘기 때문에 생기는 단점이 있습니다.
이를 해결하기 위해 한 개 로직을 추상화하여 배치 레이어와 스피드 레이어에 적용하는 형태를 고안한 트위터의 서밍 버드가 있었지만, 결국 컴파일 이후에는 배치 레이어와 스피드 레이어에 각각 디버깅과 배포를 해야했기 때문에 문제가 완벽하게 해결되지는 못했습니다.
이러한 람다 아키텍처의 단점을 해소하기 위해 제이 크랩스는 카파 아키텍처를 제안했습니다.
[카파 아키텍처]
- 카프카를 최초로 개발한 개발자 제이 크랩스(Jay Kreps)가 제안
- 배치 레이어를 제거하고 모든 데이터를 스피드 레이어에서 처리
- 배치 레이어 때문에 발생한 로직의 파편화, 디버깅, 배포, 운영 분리에 대한 이슈 제거
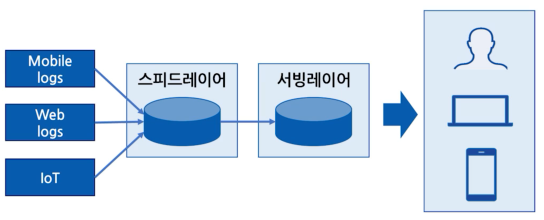
카파 아키텍처는 람다 아키텍처와 유사하지만, 배치 레이어를 제거하고 모든 데이터를 스피드 레이어에 넣어서 처리한다는 점이 다릅니다. 람다 아키텍처에서 단점으로 부각되었던 로직의 파편화, 디버깅, 배포, 운영 분리에 대한 이슈를 제거하기 위해 배치 레이어를 제거한 카파 아키텍처는 스피드 레이어에서 모든 데이터를 처리하므로 엔지니어들이 효과적으로 개발과 운영을 가능하게 했습니다.
[스트리밍 데이터 레이크 아키텍처]
- 2020년 카프카 서밋에서 제이 크랩스(Jay Kreps)가 제안
- 배치 데이터, 스트림 데이터 처리를 스트림 레이어에서 처리
- 처리 완료된 데이터를 스피드 레이어에 저장
- 마치 카프카가 하둡을 대체하는 것과 유사

2020년 카프카 서밋에서 제이 크랩스는 카파 아키텍처에서 서빙 레이어를 제거한 스트키밍 데이터 레이크를 제안했습니다.
제이 크랩스는 람다 아키텍처에서 스피드 레이어로 사용되는, 카프카의 분석과 프로세싱을 완료한 거대한 용량의 데이터를 오랜 기간 데이터를 저장하고 사용할 수 있다면, 서빙 레이어를 제거하여 서빙 레이어와 스피드 레이어가 이중으로 관리되는 운영 리소스를 줄일 수 있다고 생각했습니다.
데이터가 필요한 모든 고객과 서비스 애플리케이션은 카프카를 창조함으로써 데이터의 중복, 비정합성과 같은 문제에서 벗어날 수 있게 되는 것입니다.
하지만 아직은 카프카를 스트리밍 데이터 레이크로 사용하기 위해 개선해야 하는 부분이 많이 남아있습니다.
먼저 자주 접근하지 않는 데이터를 비싼 자원을 들여 유지할 필요가 없습니다. 카프카 클러스터에서 자주 접근하지 않는 데이터는 오브젝트 스토리지와 같이 저렴하고 안전한 저장소에 옮겨 저장하고, 자주 사용하는 데이터만 브로커에서 사용하는 구분 작업이 필요합니다.
카프카 클러스터가 단계별 저장소를 가질수 있도록 추가 기능을 개발중에 있고, 아마도 가까운 미래에는 콜드 데이터는 오브젝트 스토리지에, 핫 데이터는 카프카에서 활용할 수 있게 될 것으로 보입니다.