[데이터 파이프라인에 필요한 4가지]
- 높은 처리량, 확장성, 영속성, 고가용성
[카프카 특징#1 - 높은 처리량]
** 컨슈머/프로듀서가 브로커와 통신할 때 데이터를 묶어(배치) 전송
** 파티션 개수만큼 컨슈머를 늘려서 병렬 처리량을 늘릴 수 있음
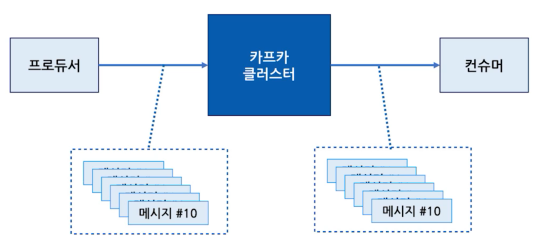
카프카는 프로듀서가 브로커로 데이터를 보낼 때와 컨슈머가 브로커로부터 데이터를 받을 때, 데이터를 묶어서(배치) 전송합니다.
많은 양의 데이터를 송/수신할 대 맺어지는 네트워크 비용은 무시할 수 없는 규모입니다. 동일한 양의 데이터를 보낼 때 네트워크 통신 횟수를 최소한으로 줄이면, 동일 시간 내에 더 많은 양의 데이터를 전송 가능합니다.
많은 양의 데이터를 묶음 처리하는 배치로 빠르게 처리할 수 있기 때문에, 카프카는 대용량 실시간 로그 데이터를 처리하는데 적합합니다. 또한 카프카는 파티션과 컨슈머 개수를 늘려서, 병렬 처리량을 늘려서 동일 시간당 처리량을 극대화할 수도 있습니다.
[카프카 특징#2 - 확장성]
** 데이터의 양이 많아지거나 적어짐에 따라 무중단 스케일인/아웃 가능
** 처음에는 작은 서버 개수로 시작
** 데이터의 양이 많아지면 서버를 늘려서 대응 가능
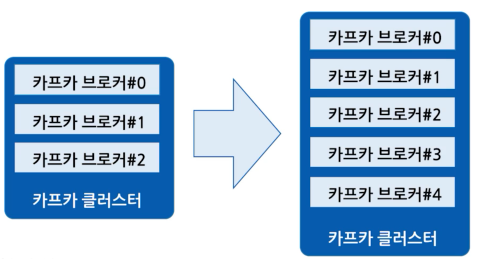
데이터 파이프라인에서, 데이터가 얼마나 들어올지 예측하기는 매우 어렵습니다. 예상치 못한 특정 이벤트로 인해 100만 건 이상의 데이터가 갑자기 들어올 수도 있습니다. 카프카는 이러한 가변적인 환경에서도 데이터를 안정적으로 확장 가능하도록 설계되어 있습니다.
데이터가 적을 때는 카프카 클러스터의 브로커를 최소한의 개수로 운영하다가, 데이터가 많아지면 브로커 개수를 늘려서 스케일 아웃(Scale-out)할 수 있습니다. 반대로 데이터가 적어지고, 추가 서버들이 필요 없어지면 브로커 개수를 줄여서 스케일 인(Scale-in) 할 수 있습니다.
카프카의 스케일인/아웃 과정은 클러스터의 무중단 운영을 지원하기 때문에, 365일-24시간 데이터를 처리해야 하는 커머스와 은행 같은 BM에서도 안정적인 운영이 가능합니다.
[카프카 특징#3 - 영속성]
** 파일 시스템에 데이터를 저장
** 브로커에 이슈가 발생하여 종료되더라도 데이터 재사용 가능

영속성이란 데이터를 생성한 프로그램이 종료되더라도, 사라지지 않는 데이터의 특성을 의미합니다.
카프카는 다른 메시징 플랫폼과 다르게 전송받은 데이터를 메모리에 저장하지 않고, 파일 시스템에 적재합니다.
파일 시스템에 데이터를 적재하고 사용하는 것은, 보편적으로 느리다고 생각될 수 있지만 카프카는 OS 레벨에서 파일 시스템을 최대한 활용할 수 있는 방법을 적용했습니다.
OS에서는 파일 I/O 성능 향상을 위해 페이지 캐시 영역을 메모리에 따로 생성해서 사용하는데, 페이지 캐시 메모리 영역을 사용하여 한 번 읽은 파일 내용은 메모리에 저장시켰다가 다시 사용하는 방식이기 때문에 카프카가 파일 시스템에 데이터를 저장하고 전송 하더라도, 처리량(속도)이 높은 것입니다.
디스크 기반의 파일 시스템을 활용한 덕분에, 브로커와 애플리케이션이 장애 발생으로 갑자기 종료되더라도, 프로세스를 재시작하여 안전하게 데이터를 다시 처리할 수 있다는 장점이 있습니다.
[카프카 특징#3 - 고가용성]
** 일부 브로커에 이슈가 생기더라도 데이터 처리 지속 가능
** 온 프레미스/퍼블릭 클라우드에 적합한 브로커 옵션들이 준비됨

3개 이상의 서버들로 운영되는 상용 환경의 카프카 클러스터는, 일부 서버에 장애가 생겨도 무중단으로 안정하고 지속적으로 데이터를 처리할 수 있습니다.
클러스터로 이루어진 카프카는 데이터의 복제를 통해, 고가용성의 특징을 가집니다. 프로듀서로 전송받은 데이터를 여러 브로커 서버들 중 1대에만 저장하는 것이 아니라, 또 다른 브로커 서버에도 저장하는 것입니다.
한 서버에 장애가 발생하더라도, 복제된 데이터가 나머지 브로커 서버에 저장되어 있으므로 저장되어 있는 브로커 서버를 기준으로 지속적으로 데이터 처리가 가능합니다.
'~2022 > Apache Kafka' 카테고리의 다른 글
| [Apache Kafka] 6. 카프카 클러스터 (0) | 2021.11.11 |
|---|---|
| [Apache Kafka] 5. 카프카 브로커 (0) | 2021.11.11 |
| [Apache Kafka] 4. 의미 있는 토픽 이름 작명 방법 (0) | 2021.11.11 |
| [Apache Kafka] 3. 레코드, 파티션, 토픽 (0) | 2021.11.11 |
| [Apache Kafka] 1. 카프카의 탄생 (0) | 2021.10.28 |